CHATGPT CROWEMIND
Redesign of Crowemind ChatGPT for Internal Data Classification Selections at the Enterprise Level
OVERVIEW:
The task was to redesign the internal interface of Crowemind ChatGPT used by Crowe to classify sensitive and non-sensitive data within its knowledge base. This feature was crucial for the organization to ensure compliance with industry regulations, improve security, and manage data access. The existing interface lacked intuitive workflows, had a high error rate, and created friction for employees during the data classification process. The goal was to create a seamless, user-friendly experience that could be scaled across various departments.
Role: Lead UX & UI Designer, Consultant
Project Duration: 3 months
Client: Crowe
Team: UX/UI Designers, Data Architects, Software Engineers, Project Managers,
Tools Used: Figma, Miro, Jira
CHALLENGES:
Complex Data Structures: The enterprise dealt with various forms of data—classified, sensitive, confidential, and general. This required a solution that allowed users to easily categorize information while adhering to company policies.
User Segmentation: Different departments had varied requirements for data handling. A one-size-fits-all solution wasn’t feasible.
Compliance and Security: The UX had to align with the organization's stringent data protection protocols and industry regulations, making security a central consideration.
Legacy System Integration: The new interface needed to integrate seamlessly with existing systems and databases to avoid any operational downtime.
RESEARCH & DISCOVERY
Stakeholder Interviews:
The first phase involved conducting in-depth interviews with stakeholders, including data managers, compliance officers, and end users from different departments. This helped in understanding the bottlenecks in the current system and gathering diverse user needs.
Key Insights:
Difficulty in Classifying Data: Users found it challenging to differentiate between similar classification categories.
Lack of Customization: Some departments needed more granular data classification options, while others preferred simplified selections.
User Frustration with Error Messages: Poor error feedback often led to delays in the process.
Design Objectives:
Improved Data Classification Workflow: Simplify the process for users to classify and reclassify data with fewer steps.
Error Prevention & Feedback: Implement intuitive error handling to guide users in making the correct choices.
Customizability: Ensure the interface could be customized based on department needs without overloading the user with options.
Scalable Security Features: Incorporate security elements seamlessly without disrupting user tasks, ensuring compliance with enterprise security policies.
Wireframing & Prototyping

Low-Fidelity Wireframes:
We began with low-fidelity wireframes to conceptualize a simplified data classification flow. Early feedback sessions were conducted with users to validate the direction and focus on pain points.
Quick Categorization: Designed a drag-and-drop interface that allowed users to easily move documents into predefined categories.
Progressive Disclosure: To prevent information overload, advanced options were hidden unless required, making the interface less cluttered for general users.
Guided Steps: Introduced a step-by-step wizard for complex classifications, especially for users like Data Managers.
Mid- to High-Fidelity Prototypes:
As we refined the designs, mid- and high-fidelity prototypes were created using Figma and tested with a range of users from different departments.
Key design features:
Dynamic Category Suggestions: Based on document metadata and content, the system suggested categories, reducing manual classification errors.
Error Notifications & Tooltips: Incorporated contextual error messages with suggestions on how to resolve issues, significantly reducing user frustration.
Custom Department Dashboards: Developed customizable dashboards where users could see relevant classification tasks and summaries based on their department’s specific needs.
Audit Trail Feature: Enabled compliance officers to track changes made to data classifications, including who performed the action and when, ensuring transparency.
Usability Testing
We conducted several rounds of usability testing with actual end-users across different departments to ensure the interface met their unique needs. Feedback was gathered through:
Task Completion Tests: Users were asked to complete a set of common classification tasks, and their success rate and completion time were measured.
Satisfaction Surveys: Post-task surveys were used to measure user satisfaction, gathering both quantitative and qualitative data.
IMPLEMENTATION & HANDOFF
The final designs were handed off to the engineering team, along with a detailed design system that included:

UI components
Interaction patterns
Accessibility considerations
Security features to ensure compliance across all departments
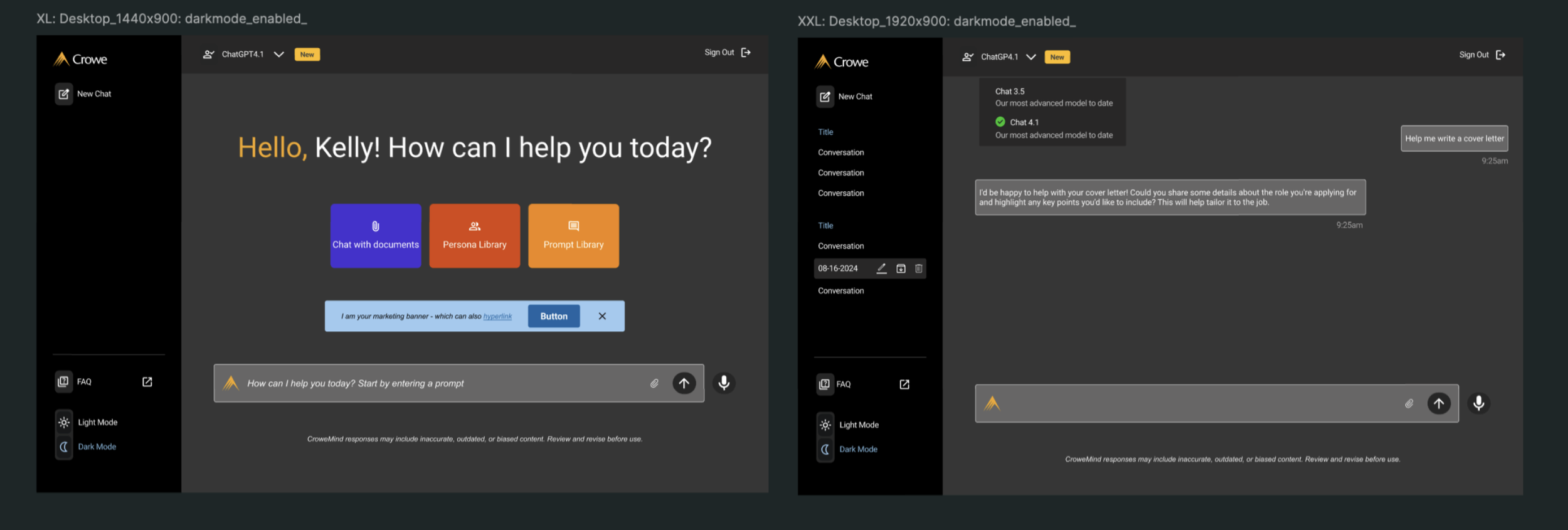
Light Mode
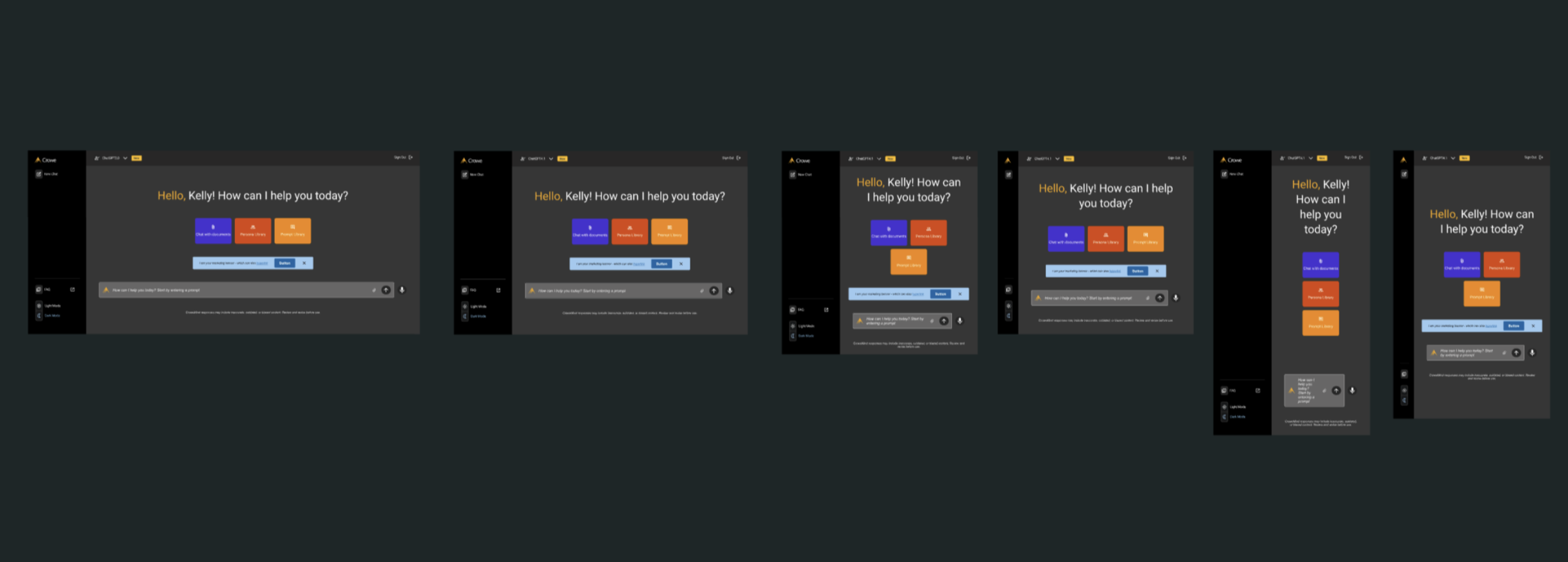
Responsive Layout
Regular check-ins during the development phase ensured that the designs were implemented as intended. I worked closely with the development team to address any roadblocks and adjusted the designs to accommodate technical constraints without sacrificing usability.
Key Learnings
Collaboration is Key: Working closely with security experts and data architects ensured that the redesign was not only user-friendly but also aligned with security protocols.
Customization Matters: Tailoring the interface to different departmental needs was essential for user adoption. A balance between simplicity for general users and advanced features for power users was critical.
Continuous Feedback Loop: Regular testing and feedback throughout the design process helped us address potential issues early and iterate quickly.